
This week in AP Statistics we explored two-variable data which is Unit 2 in the Course and Exam Description. The two quantitative variables might have a positive or negative relationship, and if they do the correlation could be anywhere from weak to strong. Sometimes, due to an observational study instead of an experiment, it’s unclear which should be the explanatory variable (horizontal axis) and which should be the response variable (vertical axis). It does not matter though, because the whole point of pitting two variables against each other is to describe their relationship and, if there is a relationship, to make predictions from the best model.
I did a little of my own exploring.
I obtained data on the nine McDonald’s burgers from this site. First I used stapplet.com to plot the data this way:

Of course the amount of fat in a burger will contribute to the number of calories so the relationship is positive.
Then I plotted the data this way:
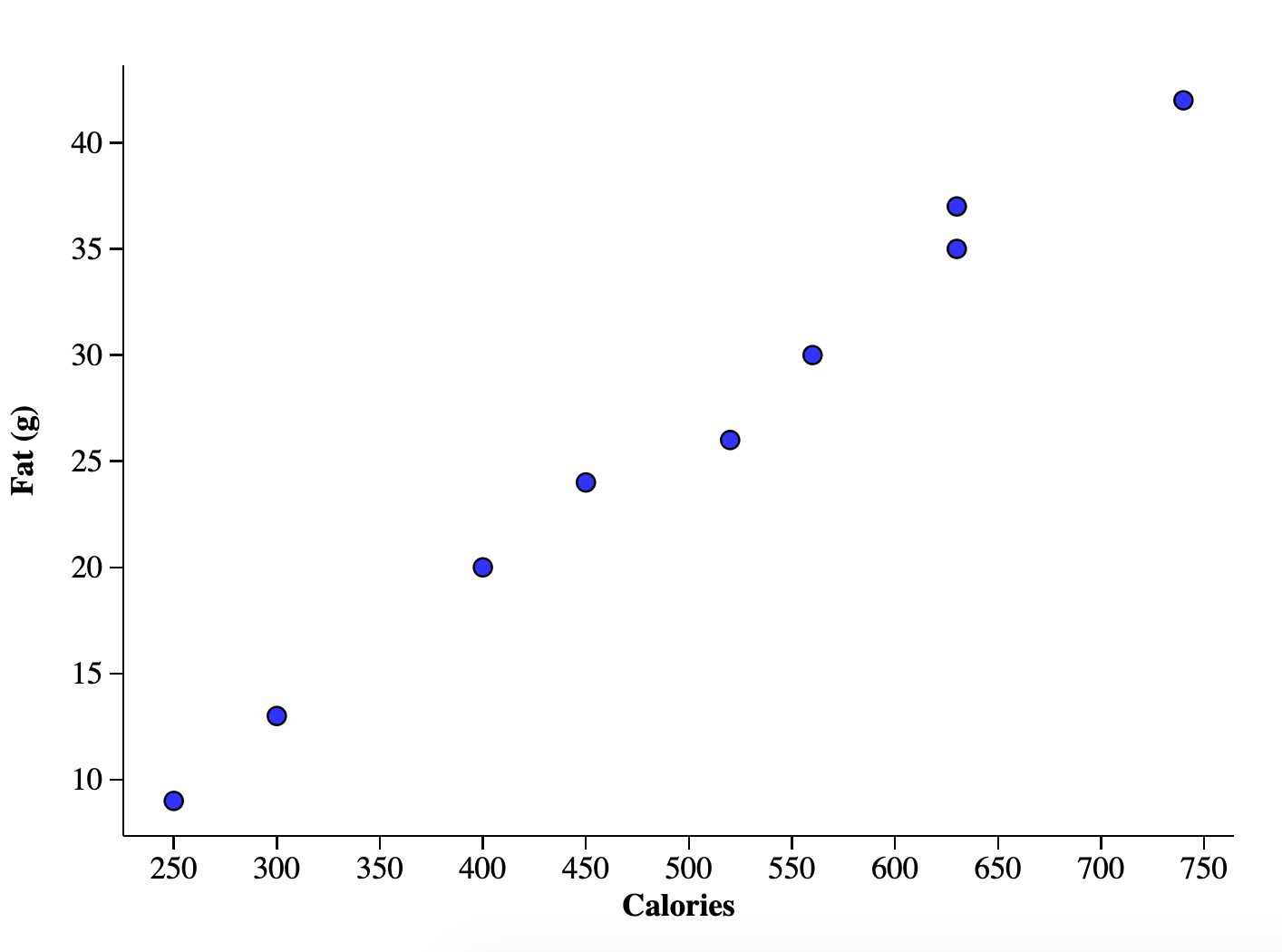
Still positive. When you interchange the x and y (here comes the algebra) on an increasing graph, the new graph is still increasing, though, if it’s linear, the slope will be reciprocated. This slope feature is true (here comes the calculus) when finding the derivative of an inverse function too. I also knew the r-value (correlation coefficient) would be exactly the same for both scatterplots and the y-intercept would be different. So that’s what I understood deeply from algebra.
Here is the r-value and least squares regression line for the first scatter plot where Fat (g) is the input, or explanatory variable.

Here is the r-value and least squares regression line for the second scatter plot where Calories is the input, or explanatory variable.

Yep. Exactly what I thought. The slopes are reciprocals, i.e. 1/14.65 = 0.068. The r-values are the same, hence the r^2 values are the same. The y-intercepts are different. Like I thought. The n=9 makes sense because the number of burgers is nine. I felt smug for a New York minute. But wait a minute, what is going on with s? Why isn’t that the same? This took me longer to understand than I would care to admit. But I figured it out and I didn’t even have to email Luke, a Stats Medic.
What is “s” anyway? It represents the average distance that the actual values are from the predicted values. I mean, either model will work as well for predicting so shouldn’t the standard error of the estimate be the same? So I calculated the residuals for the iconic Quarter Pounder with Cheese, located at (26, 520) on the first graph and at (520, 26) on the second graph.

Slowing down and using some paper to scratch out what was going on helped. Now I understood that the s-values are different because s tells us the tells us how far off the typical predicted y-values are from the actual y-values. On one graph the y-values are in the 100s and on the other graph the y-values are in the 10s, so that made sense to me. If you are predicting calories from fat, then to be off by 28 calories is ok just as predicting fat from calories to be off by about 2 grams is ok. There are 9 calories in one gram of fat. But now I had another question.
The linear model underestimated for the Quarter Pounder when the explanatory variable was fat and overestimated when the explanatory variable was calories. Was this going to be true for each of the other eight burgers? Why? I’ll leave you to chew on that for a while, and if you want, you can put your explanation in the comments.
You might like my other AP Stats posts…

If you are below the graph in the vertical direction, you will be above it in the horizontal direction, and vice versa. So if you overestimate one way, you will underestimate in the other.
Did you check it for all of the McDonald’s burgers?
Pingback: What I Gained in 2023: A Year of AP Stats | Math, Teaching, and Teaching Math